
Against AI Detection 2: Are detectors even useful?
When faced with the unknown, humanity is always tempted by simple solutions. In the (probably very short) era of large language models, these are the AI output detectors.
The underlying idea is simple: text is pasted in a box, and the detector is able to recognise whether it comes from a certain model checking the sequence of words (tokens) against the weights of the model. Companies know that the idea is simple and appealing, so several detectors have quickly appeared in the wild, like OpenAI’s own detector, ZeroGPT, Originality.ai, and Turnitin’s in-built AI detection. They will tell you that their detectors are validated on a dataset with high sensitivity and specificity, which is probably true. This does not mean that they work as intended.
I believe that AI detection should not be part of the new policies developed for higher education, and the goal of this post is to explain why I believe this. While writing it, it became very long, so I am splitting it into three parts:
Part 2: “Are detectors even useful?”.
This is part 2. A short summary of the arguments made in this post is:
Acceptable uses of AI are likely to also trigger detectors.
A detector’s output is not falsifiable.
Malpractice accusations are serious business.
Detectors and legitimate usage
When thinking about AI detection, most people assume that it works similarly to current plagiarism detection. There is, however, a crucial difference: plagiarism detectors are good tools. Examiners are interested in finding out whether the student copied their text from an undisclosed source, and the plagiarism detector recognises non-original text, provides the alleged source, and enables the examiner to independently verify the finding.
This is part 2, so let’s assume that accurate AI detectors can exist: these would not be good tools!
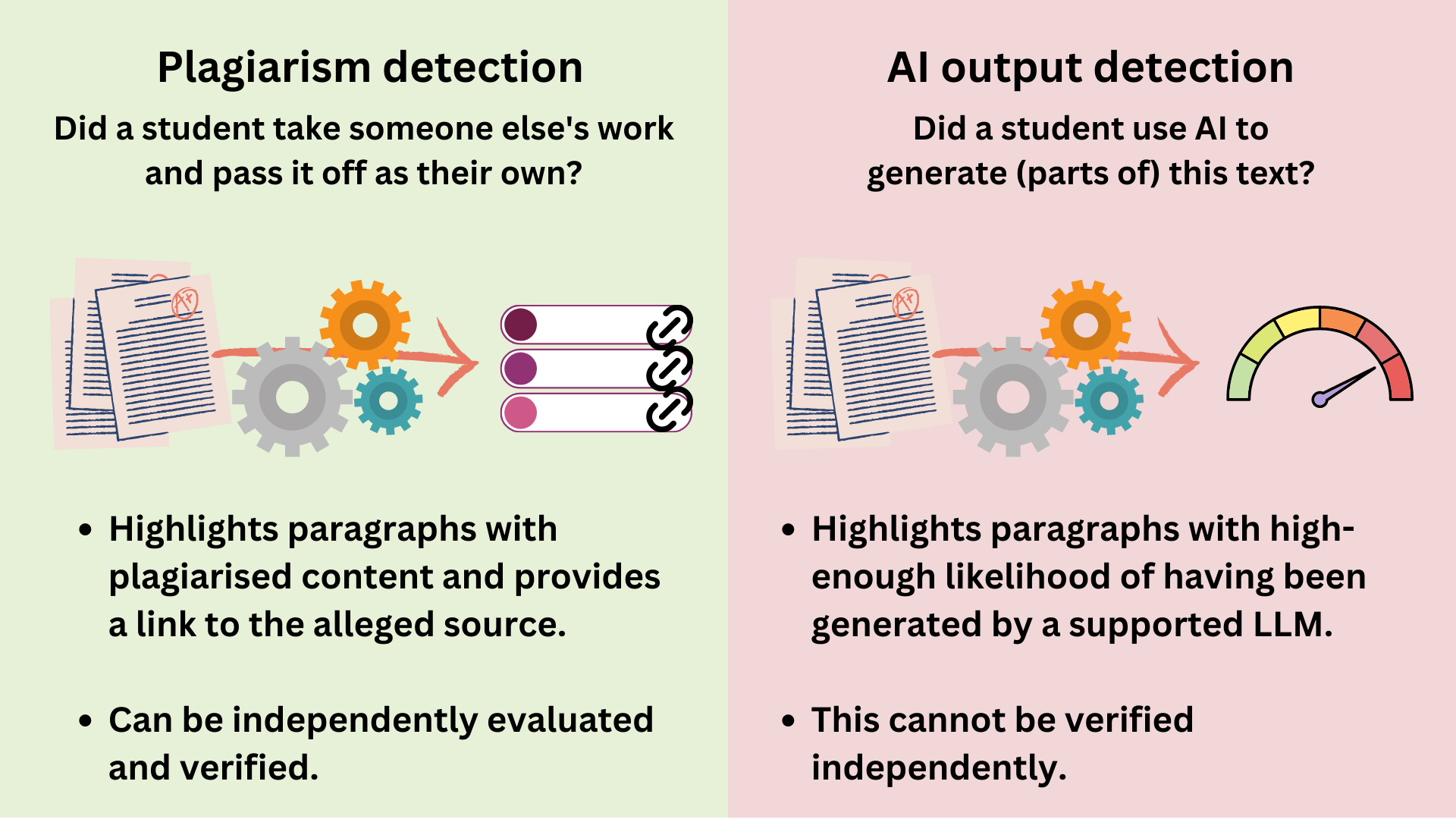
Detectors are not aligned with the goals of their intended users:
Examiners want to find out how much of the essay is the student’s own work, and how much was generated by the model.
Detectors, however, only tell how much of the text matches the modal weights distributions of a large language model.
These two goals are not necessarily aligned, unless we are in the context of a full-ban policy on generative AI usage. Thankfully, this does not seem to be the direction that the higher education sector wants to take, and does not seem like a good idea either (right?).
AI detection is trying to solve the wrong problem: here Turnitin’s CEO says that, in response to generative AI, they “are working on fingerprinting writing style, to tell when it’s changed”, with the goal of estimating the percentage of the paper that was written by AI. Then he goes on to say that their detector (launched two weeks ago) “picked up 10% of papers with 20% AI authorship”, and most educators would say that “20% is maybe fine, but 100% would be a problem” (?!?).
Even from their description, we can see that what these detectors are doing is isolating text, and then testing it against the weights distributions of ChatGPT. This does not tell us much about malpractice if we allow students to use generative AI for certain tasks.
Let us examine two students: Alice, a student that writes original content and then uses ChatGPT for review, or to paraphrase it, or to express it better; and Bob, a student that makes ChatGPT write the whole essay and then changes a few sentences (maybe through another LLM). What scores do they get on the detectors?

Again, “how much of the text is written by AI” is not what we want to measure. While with plagiarism any detected content is often malpractice, with AI detected content might be a good usage of AI, even something we seek to teach and promote.
And while, yes, a 100% result is likely malpractice, and a 0% result is likely not, it is unclear what to do with anything between 10% and 90%.
Contra me, I must admit that two negatives could potentially make a positive here. A large language model prompted on original content might deviate enough from the modal weights distributions to avoid being flagged by a detector (similar to Bob’s iteration of paraphrasing in Part 1) so, in their current incarnations, there might be some utility in AI detectors to distinguish the two.
Unfortunately, this would also mean that the output of any sufficiently elaborated prompt would be indistinguishable from original work - I think that this is true! In this instance, detectors could be useful in spotting the low-hanging fruits, meaning those essays generated with simple, minimal prompts and no paraphrasing. However, even in this very simple use case I fear that there is too much noise, and that the risks would outweigh the benefits of using detectors.
The output of an AI detector is not falsifiable
Suppose that an essay is given to an AI detector, and the output is “Most of Your Text is AI/GPT Generated”. How can this be verified?
It can’t be verified. With some clever prompt we could probably get ChatGPT to say anything close enough to a given paragraph, so reproducing the text in the model does not prove much. Further, since what the detector is picking up is a legitimate similarity in the distribution of words to the modal ones that ChatGPT could generate (recall how ChatGPT is trained on a corpus of human-generated text!), we cannot deduce more than this. Detectors can, at best, provide a hint that generative AI may have been used, or confirm the kind of malpractice that most people could spot anyway.
At the moment academics would not know what to do with an “AI-generativity report”, as there is no policy. What would happen is that each academic would make their own decisions, bringing potential bias, flaws, or even fundamental misunderstandings of the nature of ChatGPT or AI detectors.
Providing free in-browser AI detectors to users with little to no training was harmful, but perhaps inevitable. However, what has been a significantly worse decision was the implementation of mandatory AI detection in a mainstream anti-plagiarism tool used by most institutions, accompanied by claims on its reliability, providing little-to-no-guidance (read FAQ n.5!), with no emphasis on its flaws other than a general “it should not be used as the sole basis for adverse actions”.
Naturally, consequences have already materialised several times and they keep materialising, with a likely disproportionate impact on certain population groups. And, of course, students react, and the anxious ones engage with detectors to check that their original work is not a false positive. All of this is completely unnecessary: stop using detectors, and speak against them. 1

I’ll end on an optimistic note: despite the very controversial decision depicted above (why is Turnitin willing to make its servers do additional work even when the customer doesn’t want it to?).. so far, most universities in the UK managed to opt out of this feature.
Malpractice is a serious matter.
“Someone must have been telling lies about Josef K., he knew he had done nothing wrong but, one morning, he was arrested” (F. Kafka, The Trial)
Large language models can simply generate too much text. Detectors cannot avoid singling out people whose writing style happens to be similar to one of the modal incarnations of the model that they recognise.
ChatGPT is a stochastic Markov chain, whose probabilities (weights) come from training on a big corpus of human-written text. So, in some sense2, ChatGPT is more likely to write "common" sentences, that follow patterns with widespread usage. Among English speakers, who is likely to show a lower degree of originality in their prose, and hence have a higher rate of false positive with AI output detectors?
You guessed it: non-native English speakers. Turnitin’s own FAQ basically admits this, saying: “Sometimes false positives (incorrectly flagging human-written text as AI-generated), can include lists without a lot of structural variation, text that literally repeats itself, or text that has been paraphrased without developing new ideas.”
AI output detectors usage is likely to disproportionately impact non-native English speakers (which can include BAME groups), since:
Non-native English speakers’ prose is more likely to be flagged as AI-generated even when it is not.
Non-native English speakers are more likely to benefit from a Grammarly-like usage of ChatGPT, where the model can suggest better ways to express some concepts. Surely this type of usage is among those we want to encourage.
Academic integrity policies are already believed to not be race-neutral, so this could exhacerbate existing issues wherever these are present.
Anecdotally, I am a non-native English speaker, and the introduction of my 2020 PhD thesis is flagged by OpenAI’s text classifier as… “unclear”.
Update (10/07/2023): high rates of false positives among non-native English speakers are now also proved by a peer-reviewed study.
Update 2 (19/11/2023): Turnitin has critiqued the study cited above, and their critique is solid: according to tests they performed (on public datasets), such bias problems do not show up with their detector. At the moment I could not find any other study that shows evidence of bias, so more evidence is needed here. However, the general argument remains solid, and this is an example of something that should definitely be checked before any detector is used on any essay.
As we have seen, legitimate usage of AI can be flagged by detectors. If said legitimate usage is substantial, many paragraphs might be flagged. What “legitimate usage” means is currently the subject of many working groups: some institutions are banning LLMs entirely, while others choose to be more diplomatic, but there seems to be little doubt that legitimate generative AI usage exists.

Being investigated for academic malpractice is very unpleasant. Most universities apply a zero-tolerance policy on contract cheating or plagiarism, and any student found guilty faces serious consequences. So, understandably, the investigation once malpractice is suspected is taken very seriously and it proceeds with caution. In particular, it normally takes quite a bit of time to reach a verdict.
How would a student feel when they are accused of using AI because an unfalsifiable oracle identified a pattern in their writing, but they didn’t? How can students prove a negative? Alternatively (worse), how would they feel if they did use AI, but they believe their usage was compliant with whatever guidelines are in place, and they now have to prove this? Going through such an experience must be horrible in terms of mental health, anxiety, and time spent thinking about it or preparing the defence against the accusation.
Current policies take these matters very seriously, and a formal investigation only starts when multiple hints indicate a high probability of malpractice… but this is because anti-plagiarism detectors are demonstrated to be accurate, and enable the lecturer to check their output for accuracy. AI detectors do neither. Personally, if I was presented with a potential contract cheating case due to a “90%” detector output, but no obvious red flag appeared in the text... I would not know how to look at the essay and express an informed opinion. Would you?
Students already live in a world where several dystopian, invasive surveillance technologies monitor everything they do, or force them to do things in a way that is not the one they would choose. There is no reason to use generative AI as an excuse to make this worse.
Do click on all the links in this paragraph, and note that this is a sample from Reddit - not exactly the most popular social media for the current generation of students. Check TikTok on the same topic. It’s not pretty.
This is extremely simplicistic because, after the basic training, ChatGPT has been re-trained by humans to speak in a certain way, which is not necessarily the most common one.