
Against AI Detection 1: Detection does not work
When faced with the unknown, humanity is always tempted by simple solutions. In the (probably very short) era of large language models, these are the AI output detectors.
The underlying idea is simple: text is pasted in a box, and the detector is able to recognise whether it comes from a certain model checking the sequence of words (tokens) against the weights of the model. Companies know that the idea is simple and appealing, so several detectors have quickly appeared in the wild, like OpenAI’s own detector, ZeroGPT, Originality.ai, and Turnitin’s in-built AI detection. They will tell you that their detectors are validated on a dataset with high sensitivity and specificity, which is probably true. This does not mean that they work as intended.
I believe that AI detection should not be part of the new policies developed for higher education, and the goal of this post is to explain why I believe this. While writing it, it became very long, so I am splitting it into three parts:
Part 1: “Detection does not work“.
This is part 1. After a brief introduction, we categorise detection into three types, and examine the shortcomings of each:
Introduction.
Human insight.
Machine Learning detection.
Watermarked models.
Detection methods which involve surveillance or fingerprinting are instead looked at in part 3.
Edit: this paper does a much more formal and accurate job at distinguishing between several potential methods for detection.
Introduction
Large Language Models are not individuals. They are alien black boxes that have been trained to produce the output that humans thought was more appropriate. For instance, when we investigate frequent flaws in ChatGPT answers, we often see that these are the same flaws we find in humanity.

What we see every time we open a new conversation is the “median” ChatGPT, the machine defaults to certain beliefs, facts or mistakes due to its training. It is however very easy to move away from the default position, to make it express itself differently, hold different beliefs, answer in different styles. Ask it to speak like a pirate, or a professor from Washington, or a member of your favourite political party.
What current detectors (OpenAI, ZeroGPT, Originality.ai…) seem to be able to detect with varying accuracy is the output of the “default”, light-prompted ChatGPT. As soon as any effort is made to change the style, accuracy drops.
So, as usual, claims on accuracy percentages are to be taken with healthy skepticism here, as they depend on the dataset, and there is no “default” big enough dataset to properly estimate the detector’s accuracy. ChatGPT (and all LLMs) can be prompted in so many different ways that, essentially, what we’d be trying to detect here is a significant percentage of all meaningful text.
Human insight
Sometimes, you can just tell.
Many of us have already seen blatant cases of generative AI-enabled contract cheating (some call it, rather inappropriately, plagiarism). A colleague saw an essay that began with “As a large language model…”; I received a reference whose last sentence was “Regenerate response”; other people have seen other similarly ridiculous things.
Now, of course we can recognise these ones, just like we’d easily detect a submission authored by “Essay Mill Inc.” as malpractice.

This does not mean that we are any good at detecting even slightly more advanced usage of generative AI. Indeed, almost every study I am aware of… saw humans being not very good at telling human output apart from AI output [1][2][3][4][try it yourself] And that does not consider co-written content, which likely forms most of the content we could potentially be interested in detecting.
This does not mean that basic human insight is worthless. Every lecturer can and should rely on their insight to spot malpractice, including essays generated by AI without a significant contribution from the student. Usual caveats apply, as summarised in the excellent “Contract Cheating Toolkit” written by experts at the University of Manchester. However, lecturers should also not think that, surely, they can spot AI-written text, because currently available evidence points in the opposite direction. And models are only going to get better, and more sophisticated.

Machine Learning detectors
This is the biggest category, and certainly what most people think about when they talk about “AI Detectors”. In a nutshell, this is software that takes text as input and tries to identify sentences written by a large language model. This is mainly done combining two approaches:
Measurement of several statistical parameters in the text (perplexity, word-ranking, etc) comparing those to the ones detected in usual LLM output.
Classic machine learning, where a classifier is trained on a huge dataset of human-generated and AI-generated content, learning to identify the latter.
The first important point to make is that these tools, at the moment, do not work. Some can be quite good in their dataset, but the results hardly generalise to the rest of the sentences. In a way, what is being measured when a detector is tested on a given dataset (or on a few outputs) is the similarity to the original one on which the detector was developed. This compares poorly with the breadth of content that AI is able to output.
So, it makes sense that googling around you’ll find studies that see a certain detector perform very well, and studies that see the same detector fail. There is no “universal” dataset! And as models improve, they’ll be able to generate even more text, making it even harder to have a dataset able to match all they can write. It will soon be possible to train a LLM on your writing, and then ask it to emulate it!
This paper argues that this is a fundamental flaw, and that for a sufficiently complex LLM detectors can hardly perform better than a coin toss.
But we don’t have to look into the near future to see detectors failing. It is perfectly possible to break detection right now, with our current tools. To illustrate this, I’ll provide an example.
How to fool a detector
Freely available detectors are pretty bad at detecting GPT-4, so let’s use GPT-3.5. I asked it to generate 500 words on Stonehenge.

Pasting the result on ZeroGPT gives the following result:
Now we open GPT-Minus1, a tool that promises to “Fool GPT by randomly replacing words with synonyms in your text”. This is a very simple one: it just picks random words and replaces them with synonyms, sometimes inaccurately (but it highlights the replacement, which can be checked by the user), let it do its thing, and…

This is a crude and very elementary way to completely break a basic detector. Are there better detectors? Probably. And there are probably better ways to break them.
Another way of breaking a detector is making ChatGPT move away from its default persona, and therefore from the training dataset. For instance, if I ask it about Stonehenge again, but I ask it to write like a pirate…
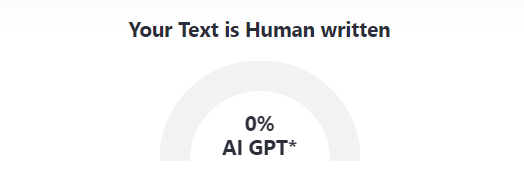
I hope I can convince you to not rely on detectors at all, but if I can’t, I ask that you at least do this: choose your favourite detector, and your favourite assignment, and dedicate 30 minutes to try and break it via creative prompts and/or paraphrasing. I expect you’ll succeed in 5 minutes.
And these are false negatives! There are also false positives, whose consequences are much worse: anyone writing in a way remotely similar to some LLM’s default persona (which, remember, are trained on human-generated text, so said persona will be quite close to the median human)… is in trouble. There is evidence of a higher rate of false positives in text written by non-native English speakers. More on this in part 2.
Watermarked models
The idea is very simple: a hidden pattern is inserted into the models, so that every output is easily detectable, and the chances of said pattern arising naturally are negligible.
A very simple implementation would be the following: words are divided into two sets (red and blue), and the model is forced to pick one word from each, alternating.

You might think that this is quite vulnerable to paraphrasing tools, and it is. However, quite surprisingly, it seems that it is possible to create “unremovable” watermarks.
The issue is another: that… it’s too late. Detection that relies on watermarking is vulnerable to any non-watermarked large language model, and these models exist right now - indeed, no popular model available right now is watermarked. And not all of them can be withdrawn.
There is a strong business incentive to keep a non-watermarked model around, and not just for essay mills. Workers will not want their boss to know that they used Generative AI, job applicants will want cover letters to be non-watermarked, and so on.
So, watermarking-based detection would have been possible, but it’s not. Which, again, means that we can’t rely on detectors, which means that we need to think about something else.