


ChatGPT's thoughts
A few days ago OpenAI announced ChatGPT plugins. Interestingly enough, instructions to the GPT-side of the plugin are given by just… telling it what to do.


The first incarnation of GPT-4 that we met was Sydney/Bing AI. Joaquin Castellano on Twitter had the insight of asking Bing itself to reveal its internal structure, and he was successful.


Despite the possibility of LLMs just hallucinating stuff, this has been replicated enough times that I’m confident it’s actually real (do it yourself!)

ChatGPT (be it 3.5 or 4) is quite different, it is in a way “the base model”. This does not mean that it is not conditioned to act in a certain way, just that prompt engineering is (almost) not being used to achieve this. Instead, RLHF (Reinforcement Learning from Human Feedback) and other forms of fine-tuning have been applied to the “raw” model to turn it into the helpful assistant that we all know and love.

Several people have noticed two things about ChatGPT:
It is not particularly concise.
The accuracy improves when the model is asked to reflect on its answers.

(there is more robust evidence on self-reflection improving the performance of a language model, but let’s keep this basic).
All this to say: it is not a coincidence that ChatGPT prefers to be verbose, write long sentences, write all the definitions and clarify its goals. It is self-prompting itself into getting it right!
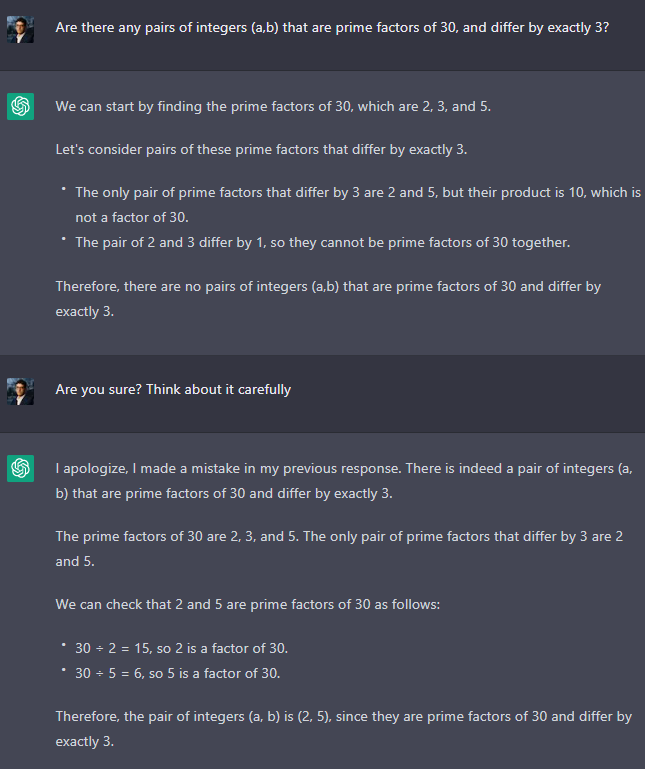
One example:


However, new conversation:

One more:

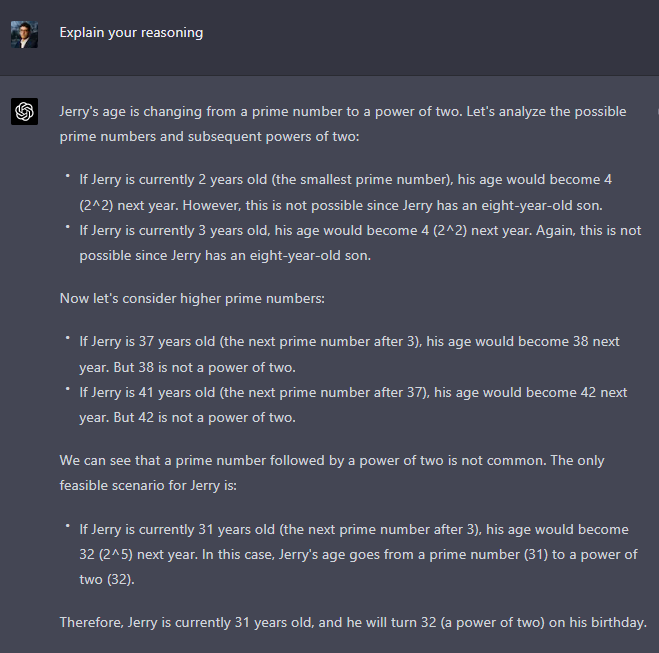
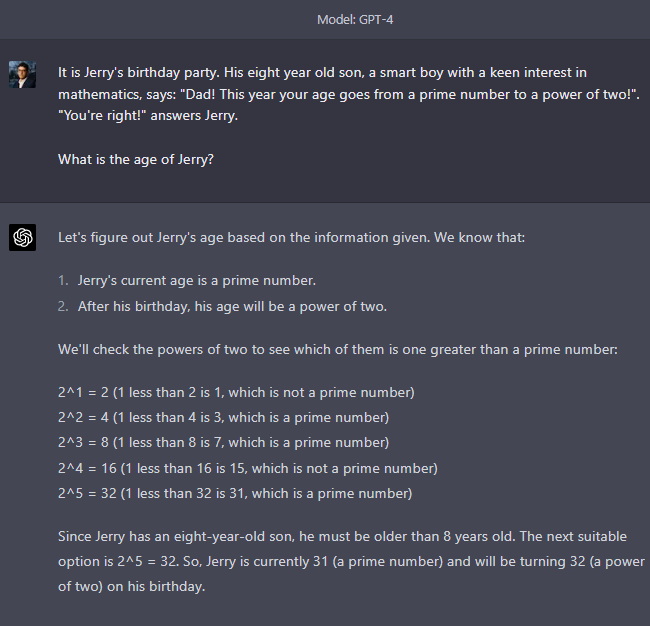
We have seen in past posts that, sometimes, it still gives a short answer, and it does not get it right at first try. Sometimes it gives a long answer and still gets it wrong. I suspect that this might be because some version of the old “be concise” prompt has now been embedded in the weights in some other way. OpenAI has very good reasons to do this (each token costs money to generate), but the very fact that this prompt was originally needed tells us that, post RLHF, ChatGPT wants to be verbose.
This behaviour could make sense if ChatGPT had an inner monologue like Bing, but… it doesn’t. As far as my understanding goes, when prompting ChatGPT we are seeing the tokens (words) as they come out, one by one.

So when ChatGPT sets the stage for an answer by rephrasing the question, defining terms, and explaining how it is going to think about the problem… all this increases the probability that the next words will actually lead to the correct answer. If a priori “39” and “31” have reasonably equal chances of following a question asking about a father’s age which is a prime number, actually spelling out the problem shifts the balance on “31” massively.
So, rambling increases accuracy… but why do the weights like rambling more than they like just straight answers? ChatGPT is trained on a huge corpus of internet-scraped text and, while several samples certainly contained detailed preambles to answers, in most cases humans… just answer the question. The thinking part takes place inside our brains, and it is not put on paper, or on the internet.
Well, I think that is because RLHF selects for accuracy. The human feedback on the answers above would be “Bad answer” on the concise ones, and “Good answer” on the rambling ones because… they are correct. And if long, rambling answers are more likely to be correct, collapsing the model onto what humans say is good is going to select for long, rambling answers even though that wasn’t the original intention.
So this is not ChatGPT knowing what to do, and it is not even ChatGPT mimicking how the human brain’s thought process works to solve problems. This could simply be a combination of humans liking human-sounding answers, and evidence that the human brain’s process yields accurate answers.
You could say that we taught it how to think, since when we allow it to think before answering that is what it does. Or, less romantic, that we twisted the weights matrix to shape it as a human mind, because that is what we understand.
 | Shoggoth with Smiley ...")
This means that, at least in maths (but I have anecdotes from other disciplines that seem to confirm this), ChatGPT-written answers are more likely than human-written answers to follow a verbose structure where the assumptions are repeated, the goal is clearly stated at the beginning, and most concepts are defined or introduced briefly.
Depending on the subject, this could look very out of place. For instance, a human-written essay about the impact of paper currency on the economy is probably not going to explain what a banknote is. If you spot such a structure in an answer or an essay, you should consider the possibility that it was written, or co-written, by ChatGPT (follow this space for more on “interim signs that something might be written by AI” very soon).
Of course, and as usual, there is a very easy workaround to this - just let it figure out the right answer the way it ‘wants’ and then follow up with “ok, now write this omitting the preamble and the basic assumptions” to submit the latter instead. But a lot of plagiarists are lazy, so this is probably going to help us catch a few.
Like everything with LLMs, strange things do happen:

It remains to ask: how does GPT-early (before RLHF) perform?
Back in the day, I played with the original version of GPT-3. It was answering randomly, and hallucinating a lot. Indeed, collapsing it onto Helpful Chatbot Assistant hurts its creativity quite a lot… perhaps making it more reliable, perhaps improving my ability to communicate it what I actually want.

One final thing that I must mention is that, from the OpenAI GPT-4 paper, RLHF does not seem to alter the model’s intelligence. It only seems to make it better at communicating with us, and writing more human-sounding answers. Make of that what you will!

